
The Spread of the Data:
VARIANCE & STANDARD DEVIATION
Module learning objectives
After successfully computing the mean, you return to the memory of the first day you had collected data. There was one teacup giraffe that was your favorite– it was relatively small with purple spots and perky tail! You begin to wonder how rare it would be to encounter a giraffe smaller than this one. To answer this question, you need to be able to calculate a measure of spread.

You might start by quantifying the simplest measure of spread, the range. This at least tells us the boundaries within which all the sample heights fall, but the range ignores important contextual information. For example, two data sets can have very different spreads but still have the same range.
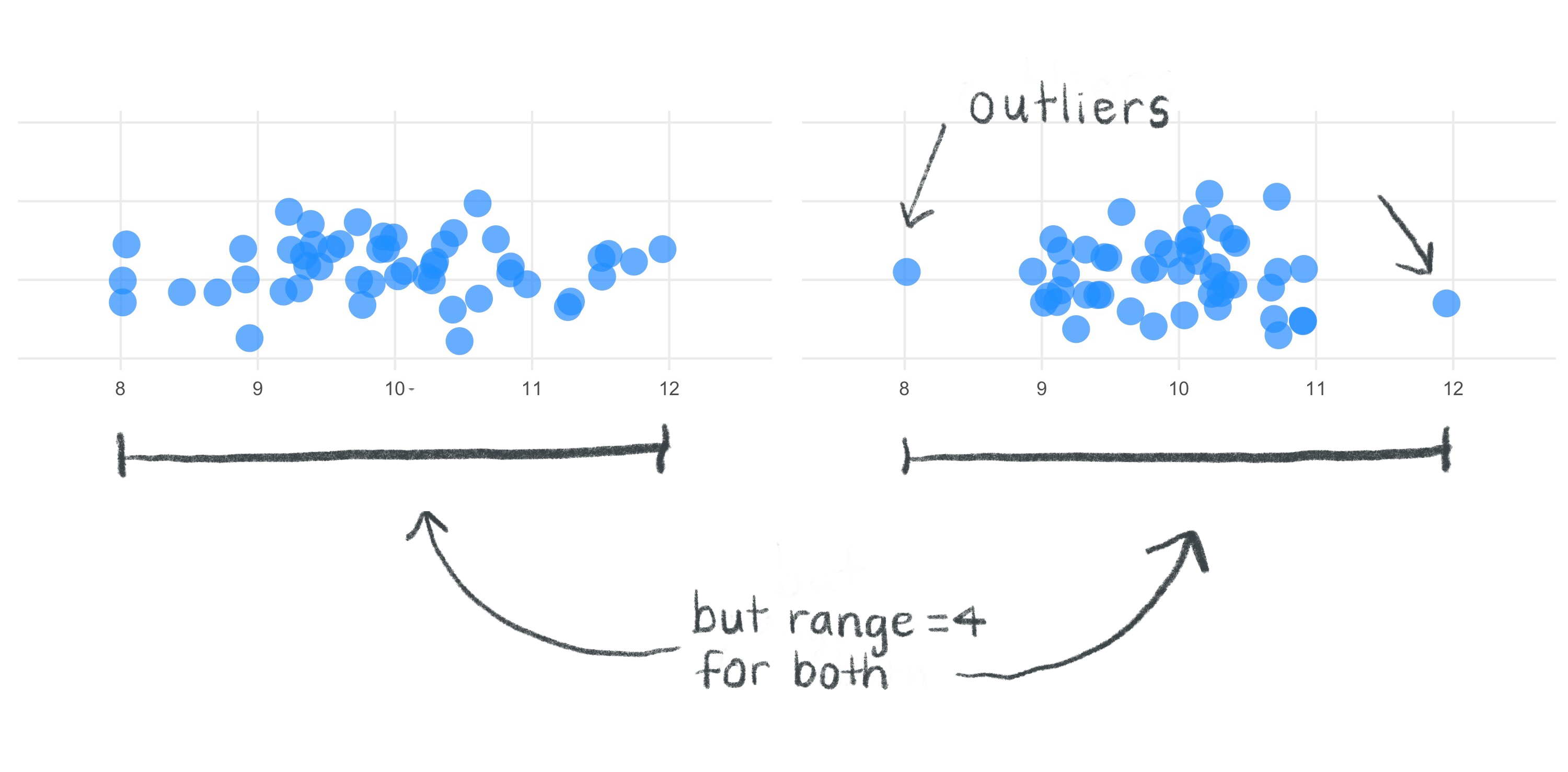
If we want to avoid undue influence of outliers for the measure of spread, the range is not good enough to provide us with a wholistic, robust measure.
What is a more stable measurement? The answer is the variance.
You need a solid understanding of variance in order to grasp the mechanics of any statistical test. But what does the concept variance really capture?

Let’s begin by going through the steps and equations for calculating the variance of a population. We’ll explain how to modify this for calculating the sample variance later on.
First, the idea is to capture how far away individual observations lie from the mean. In other words, we could subtract the mean from each observation. This is called the deviation from the mean. And since we’re calculating a population variance, we will use \(\mu\) for the mean instead of \({\bar{x}}\).
Calculating the deviations is a great start, but we’re back to the problem of needing to summarize multiple values. Since these newly calculated values are both negative and positive, we quickly realize that adding them up (like the first step when calculating the mean) would not be a productive idea since the negatives cancel the positives.
What’s the easiest thing to do when you want to retain how far away a point is from the mean irrespective of whether it’s above or below the mean? How about taking the absolute value?
Though the absolute value of the deviation would be a valid measure of distance from the mean, it turns out that it has some mathematical properties that don’t make it the best choice, especially for more complex statistial analyses involving the variance later down the line.
There is an alternative with simpler, “better behaved” mathematical properties: squaring the deviations. Squaring will always give us positive values, so the values can never cancel each other out. It’s worth pointing out, however, that a consequence of squaring deviations will tend to amplify the influence of values at extreme distances from the mean. You can read this thread for a more detailed discussion about absolute values versus squared deviations.
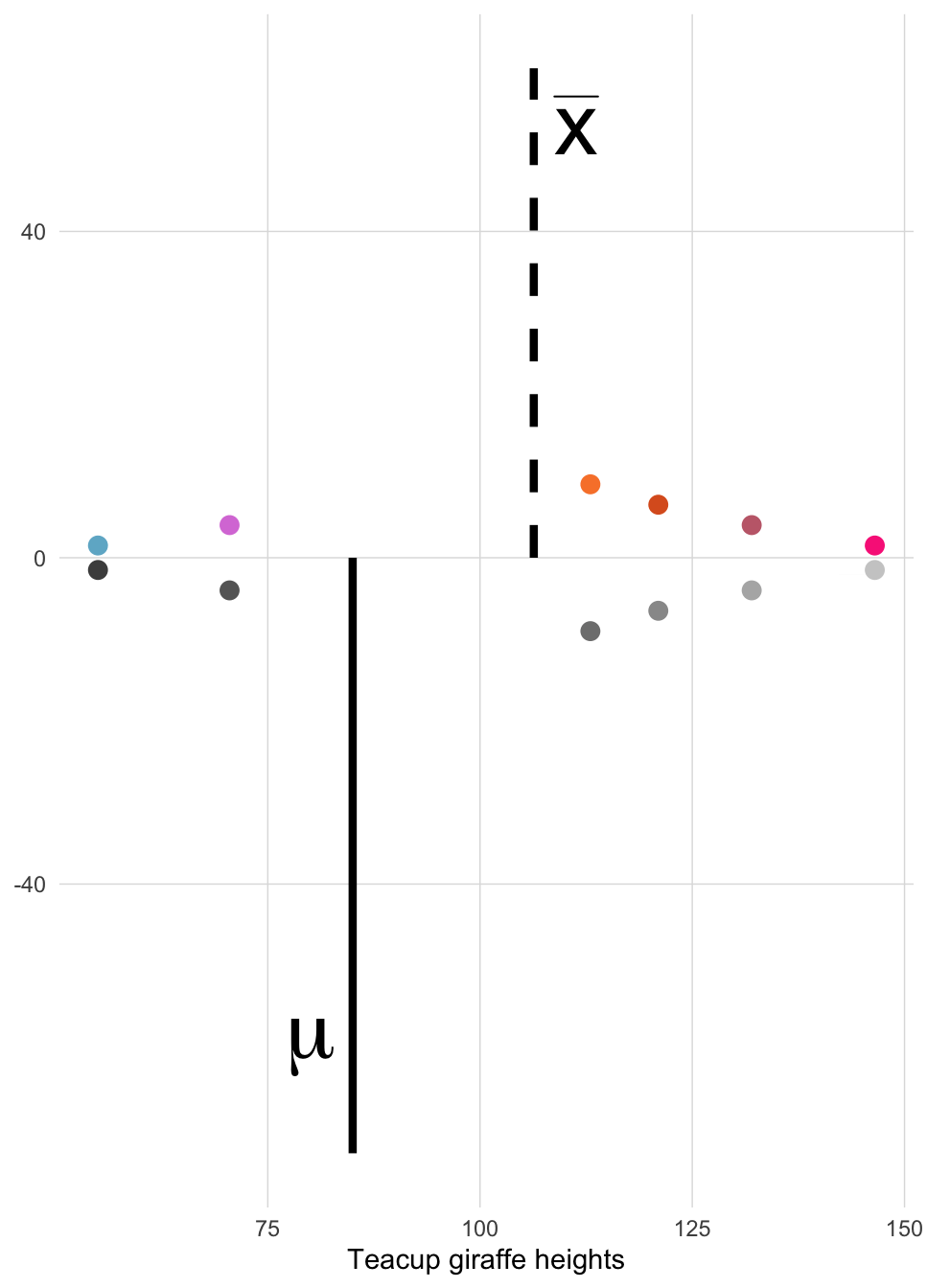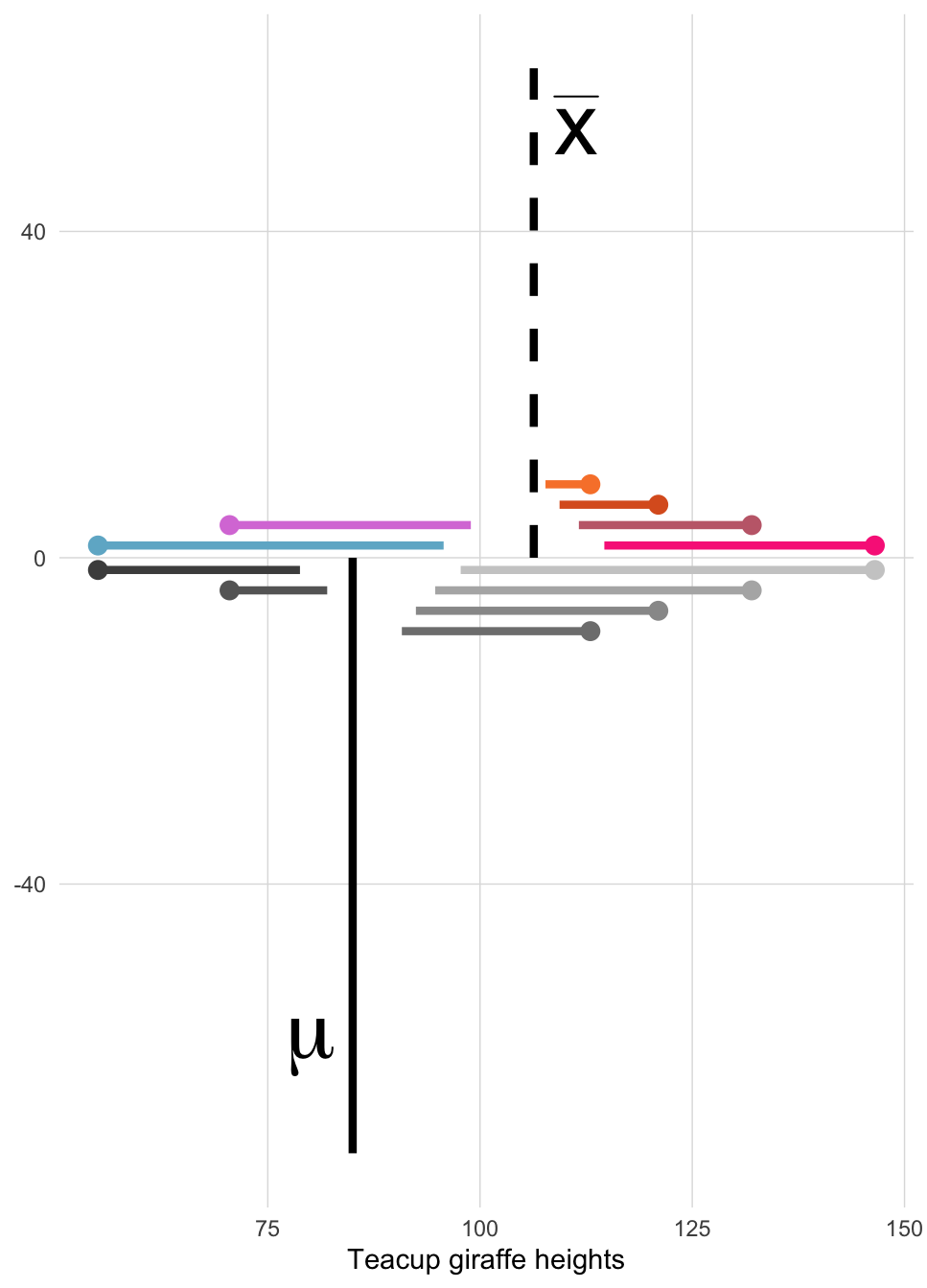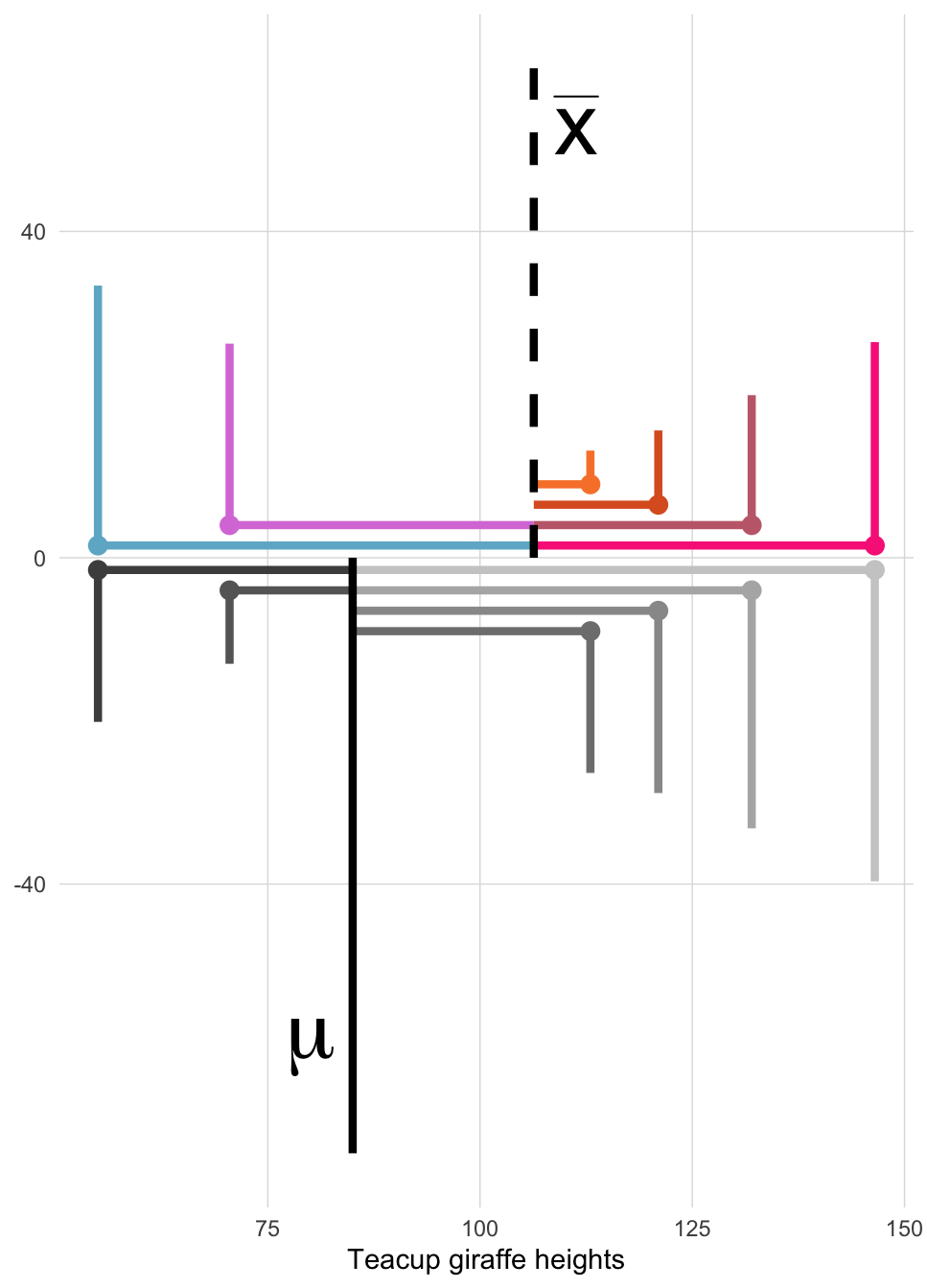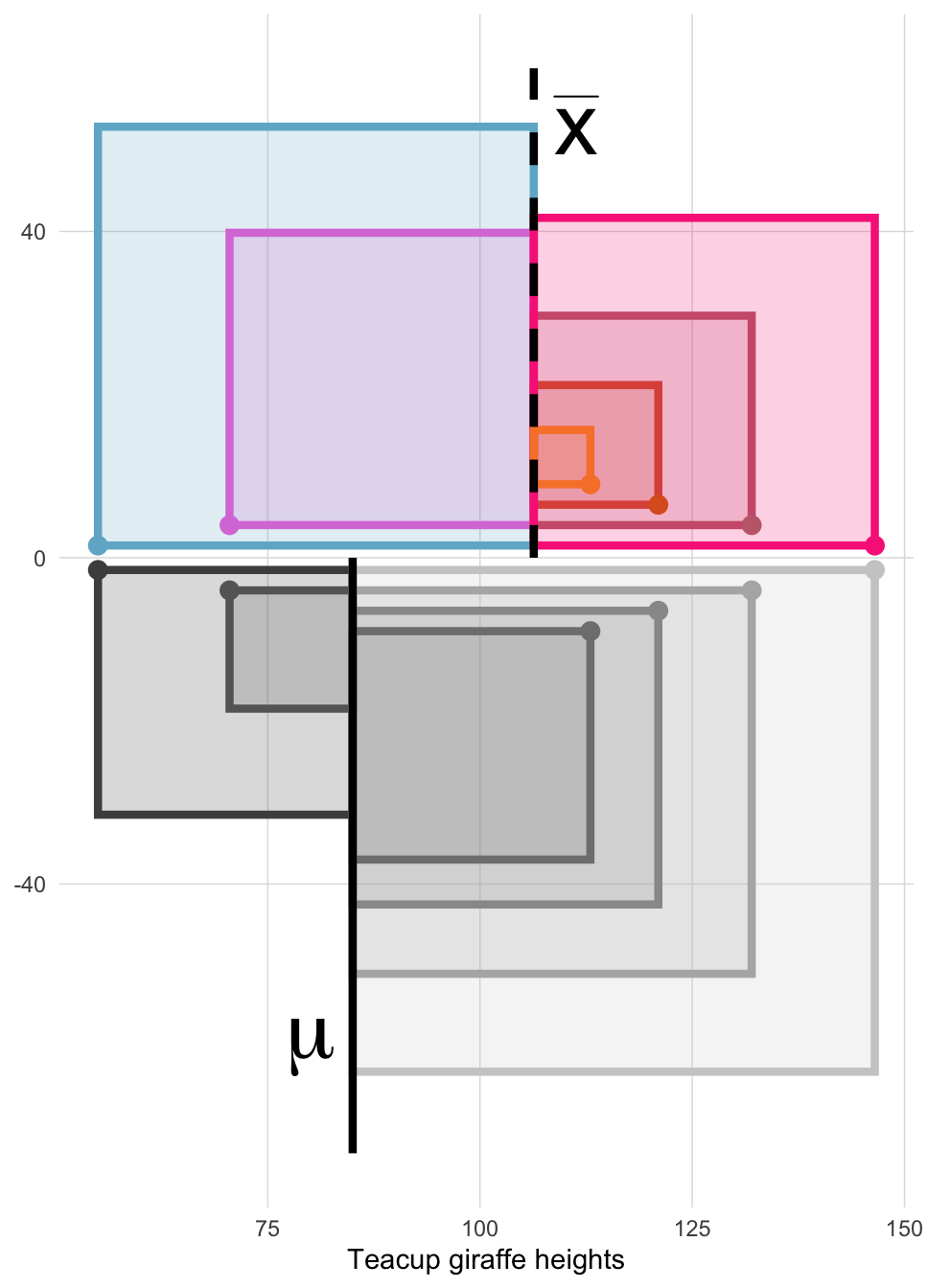
Now we have positive, squared deviation values that can be summed to a single total. We call this total the sum of squares, and the equation is shown below.
The sum of squares is an important calculation that we will see again for other statistical operations. The animation below illustrates how these sums of squares are “constructed” starting with the sample observations and then squaring each one’s distance away from the mean.
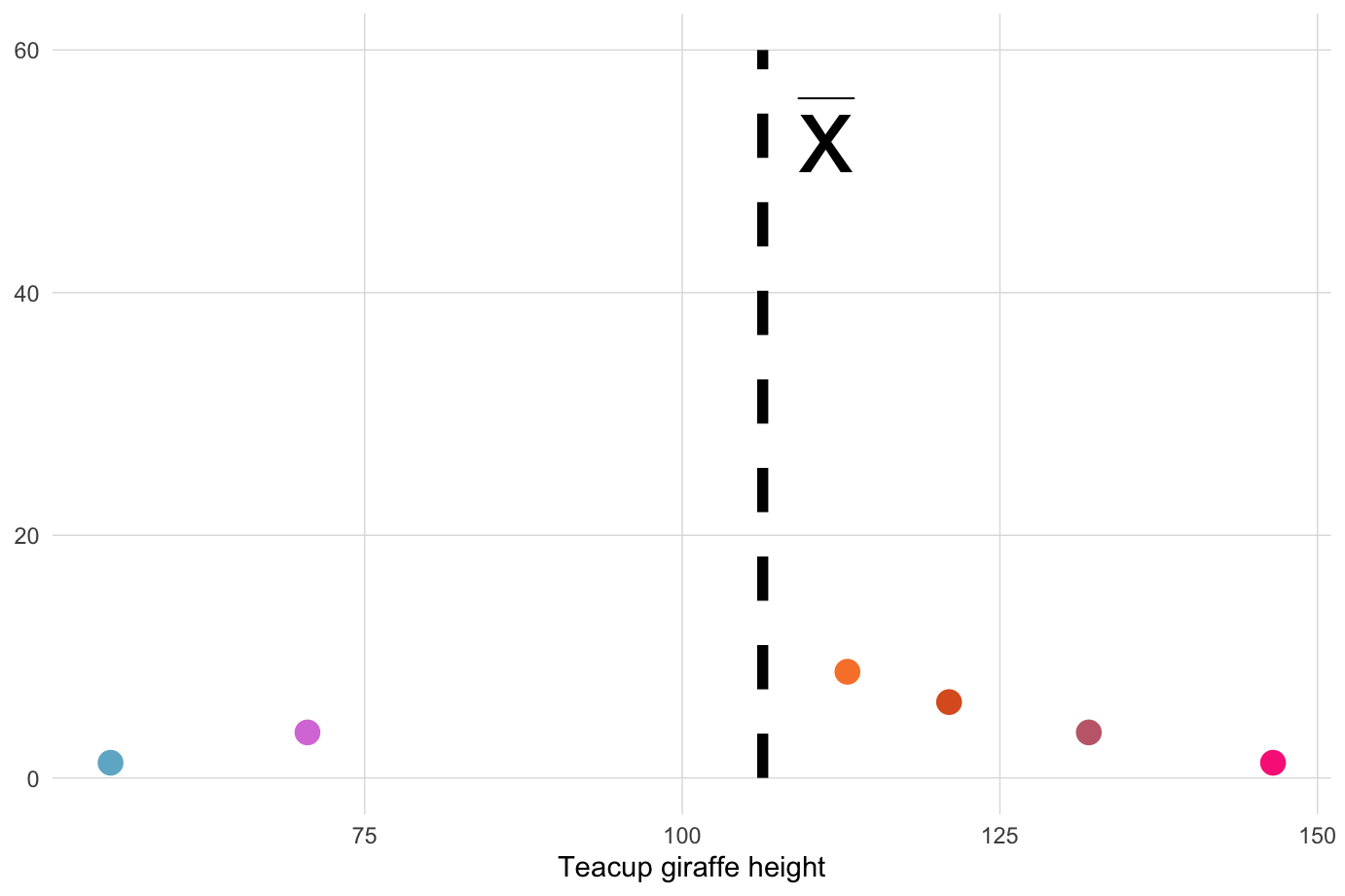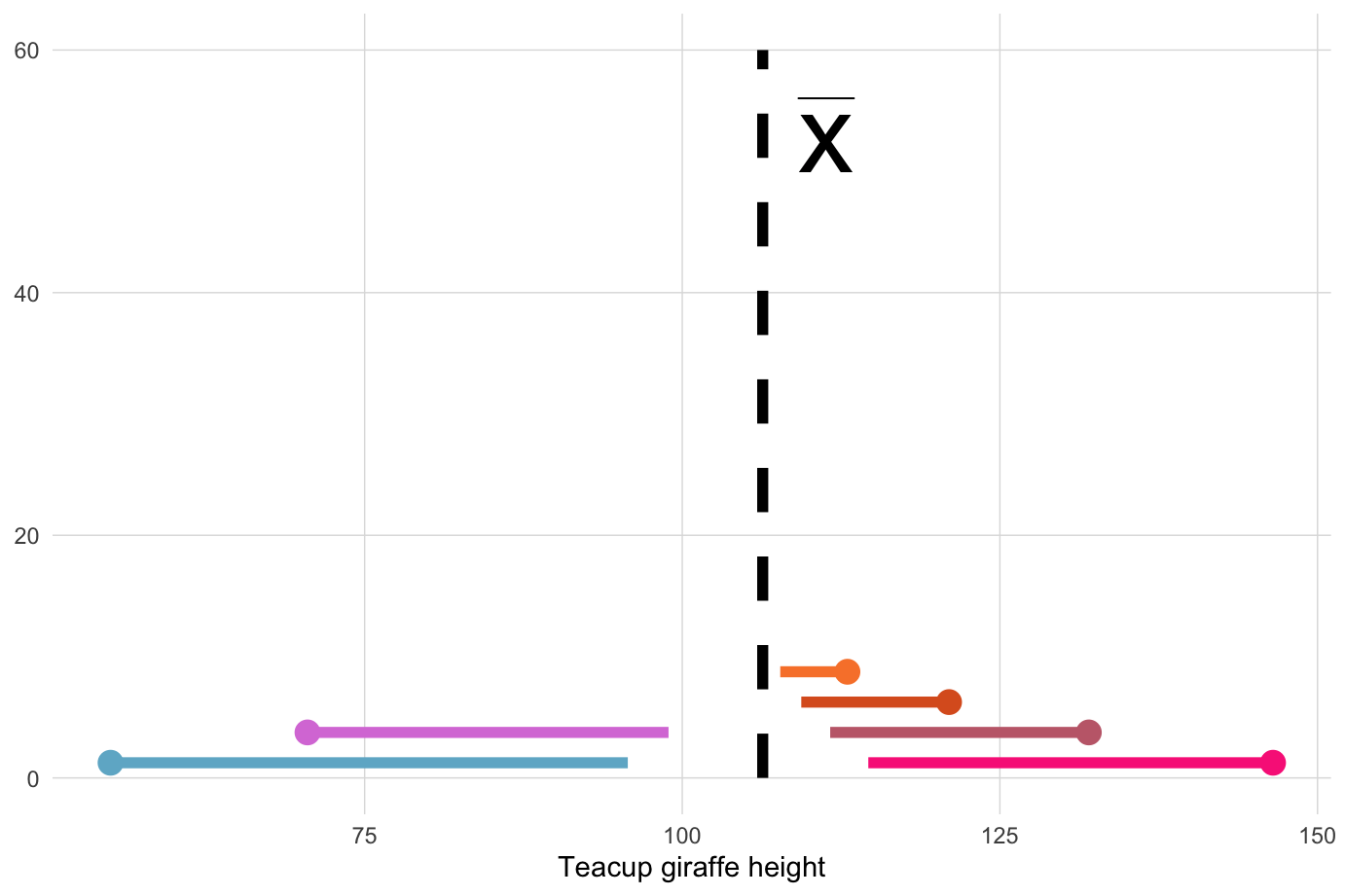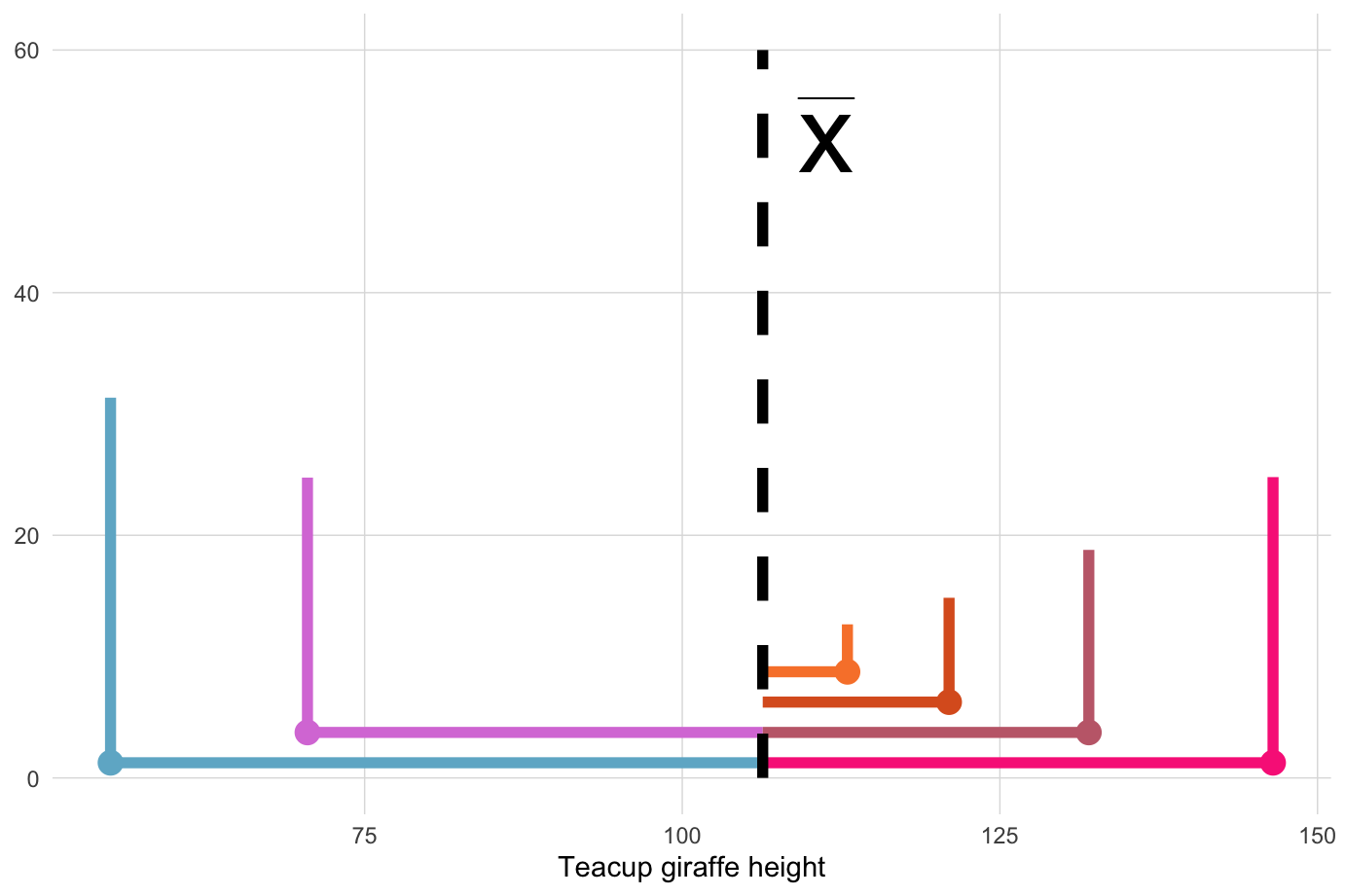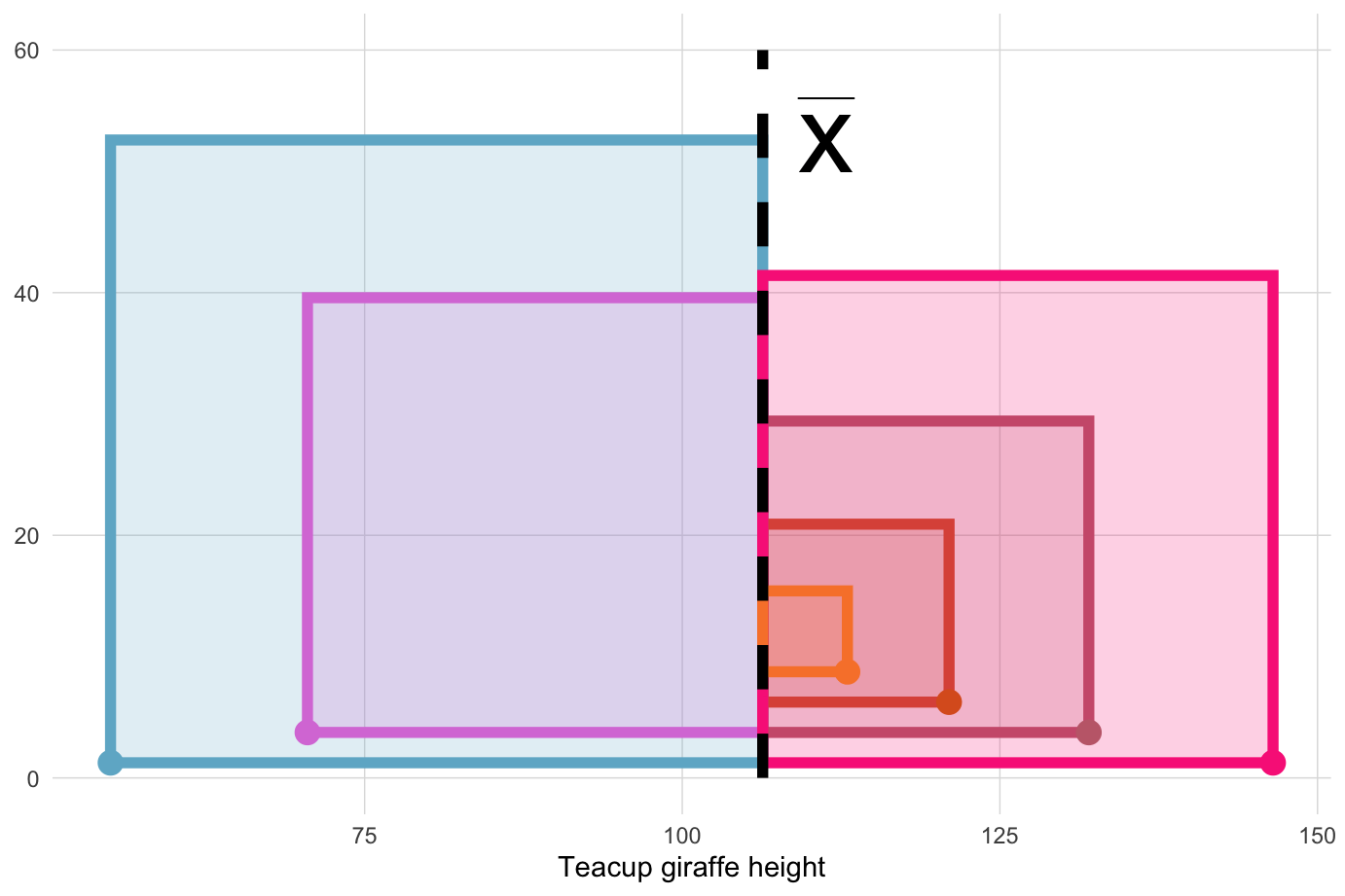
Once the squares have been “constructed”, we sum their squares, producing a single value.
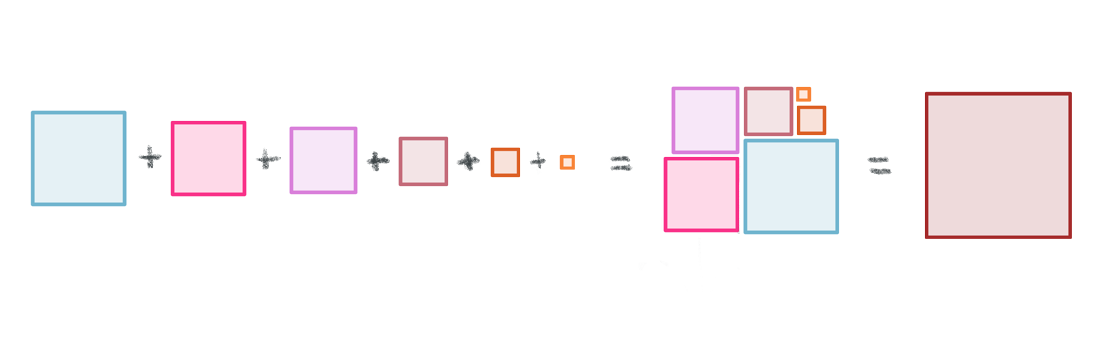
We need to take into account how many observations contributed to these sum of squares. So, we divide the sum of squares by N. This step essentially takes the average of the squared differences from the mean. This is the variance.
The problem with variance is that its value is not easily interpretable, the units will be squared and therefore not on the same scale as the mean. It would not be very intuitive to interpret giraffe heights written in millimeters squared! The standard deviation fixes that. We “un-square” the variance, and now we return to the data’s original units (millimeters). The standard deviation equation is below:
One more thing: the equations above are for calculating the variance and standard deviation of a population. In real life applications, the population equations will almost never be used during data analysis. To calculate the variance and standard deviation for a sample instead, we will need to divide by n-1 instead of N, which we explain at the end of this module. Note that we also change to the corresponding symbols for the sample mean (\(\bar{x}\)), sample size (lowercase \(n\)), and use a lowercase \(s\) in place of \(\sigma\).
When we apply this change, our equation for the sample variance, \(s^2\) is:
And for sample standard deviation, \(s\):
Since we’re now focusing on samples, let’s think about how we can apply the standard deviation in a useful way to normal distributions to predict how “rare” or “common” particular observations in a data set may be. For the normal distribution, almost all of the data will fall within ± 3 standard deviations from the mean. This rule of thumb, called the empirical rule, is illustrated below and you can read more about it here.
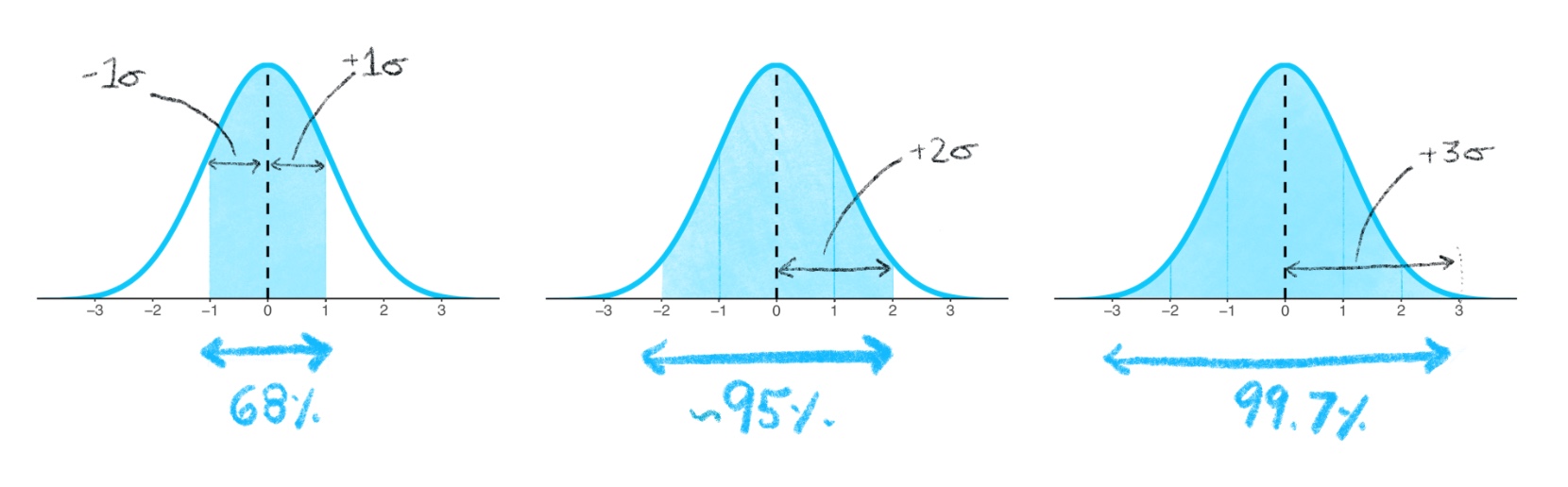
The entire normal distribution includes 100% of the data. The empirical rule states that the interval created by 1 standard deviation above and below the mean includes 68% of all the data. Observations within these bounds would be fairly common, but it would not be exceedingly rare to observe data that fall outside of these bounds.
2 standard deviations above and below the mean encompasses approximately 95% of the data. Observations that fall within these bounds include the common and also infrequent observations. Observations that fall outside of 2 standard deviations would be uncommon.
3 standard deviations above and below the mean encompass 99.7% of the data, capturing almost all possible observations in the set. Observations that fall oustide of these bounds into the extremes of distribution’s tails would be exceedingly rare to observe (but still possible if you sample large enough groups to detect these rare events!).
Let’s calculate the variance and standard deviation using 6 observations of giraffe heights from a subset of our data, including your favorite small one with the purple spots.
h <- c(113, 146.5, 132, 70.5, 121, 55)
mean(h)## [1] 106.3333We’ll plot the mean \(\bar{x}\) below with a gray line.
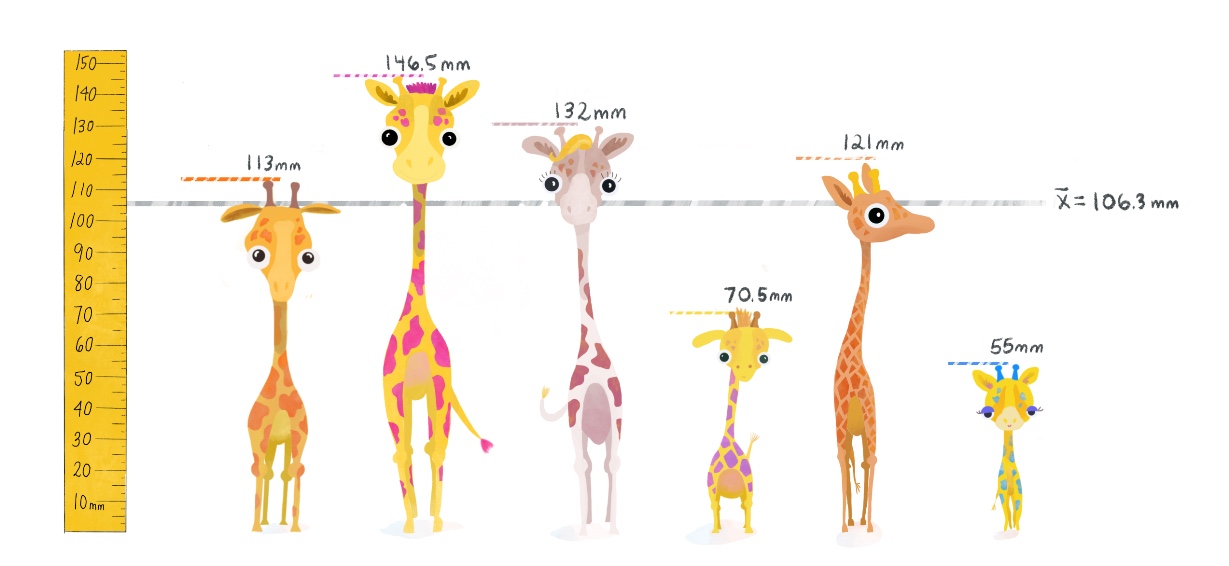 (2) Find the deviation from the mean, the difference between each giraffe’s height and \(\bar{x}\).
(2) Find the deviation from the mean, the difference between each giraffe’s height and \(\bar{x}\).
deviation <- h - mean(h)
deviation## [1] 6.666667 40.166667 25.666667 -35.833333 14.666667 -51.333333
SS <- sum(deviation^2)
variance <- SS/(length(h)-1) # Divides by N-1
variance## [1] 1290.167sqrt(variance)## [1] 35.91889Because the standard devation is a standardized score– we can now focus on particular giraffes and see whether or not they lie within 1 standard deviation of the mean.
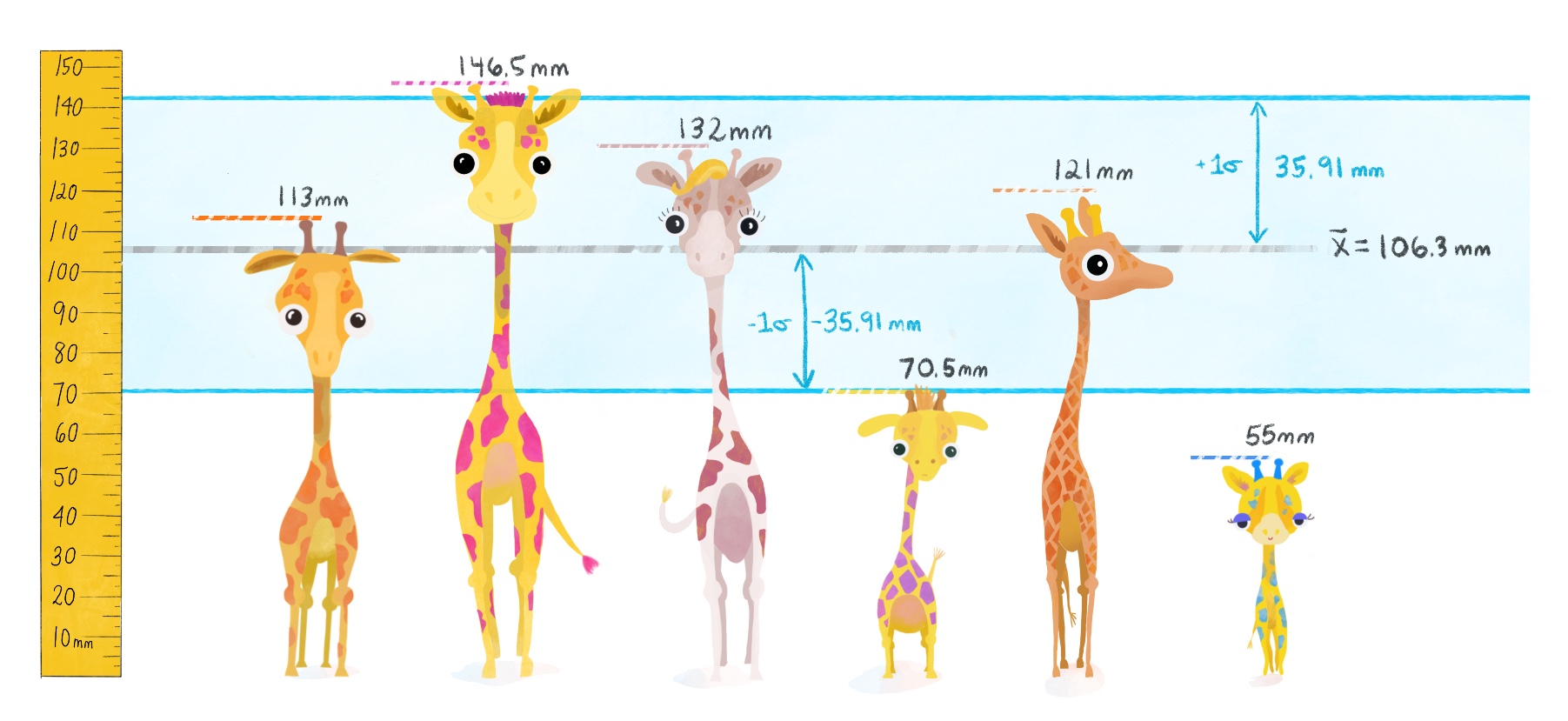
We see the little blue spotted giraffe is more than 1 standard deviation below the mean– and so we can conclude that a little guy of his height is rather short– even smaller than your favorite! Similarly, the giraffe with bright pink spots is taller than 1 standard deviation above the mean– quite tall!
Using the standard deviation and the empirical rule described earlier, we now finally have the tools to answer our original question from the start of the module: how probable it is to find a giraffe smaller than our favorite purple-spotted one?
Our giraffe of interest happens to be almost exactly 1 standard deviation below the mean, so this makes it easy to assess the probability of encountering a giraffe shorter than him.
If we assume our sample comes from a normally distributed population, then what percentage of giraffes will be shorter than the one with purple spots?
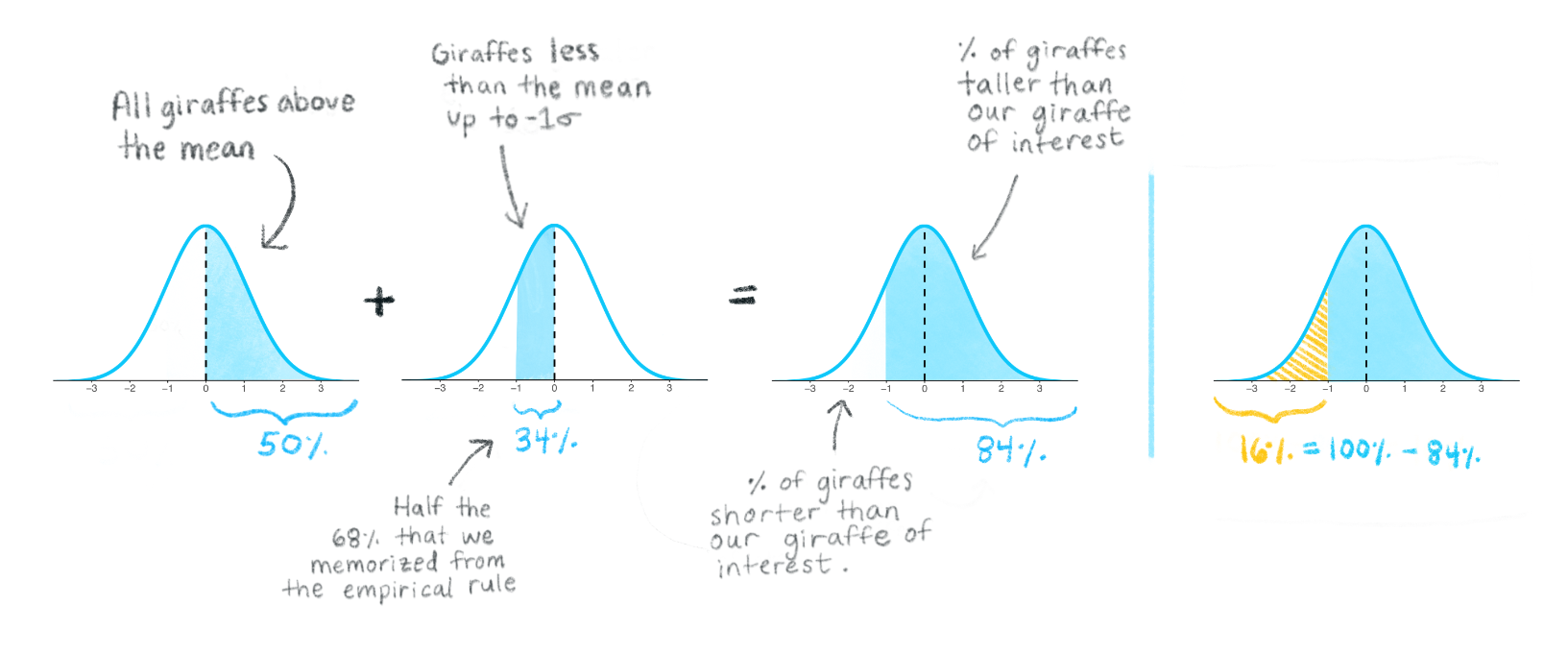
We can apply the knowledge that the full percentage area under the curve is 100%, and what we know from the empirical rule, to conclude that there is approximately 16% of giraffes will be shorter than the one with purple spots. So, it would be common to find giraffes taller than our favorite but somewhat of a treat to find ones smaller–like the blue one!
Maybe this explains why the little blue spotted giraffe is so cute— it is not so common to find ones so small!
Using (4) and (5), it’s easy to translate the equations for the variance and standard deviation into code in R.
In the window below, you will write two separate functions, one to calculate the sample variance and another to calculate the sample standard deviation. Name your functions my_variance and my_sd.
Test your functions on the vector heights_island1 and compare the output of your “handwritten” functions with the base R function of var( ) and sd( ).

We have to correct the calculated variance by dividing by \(n-1\). Let’s explain why:
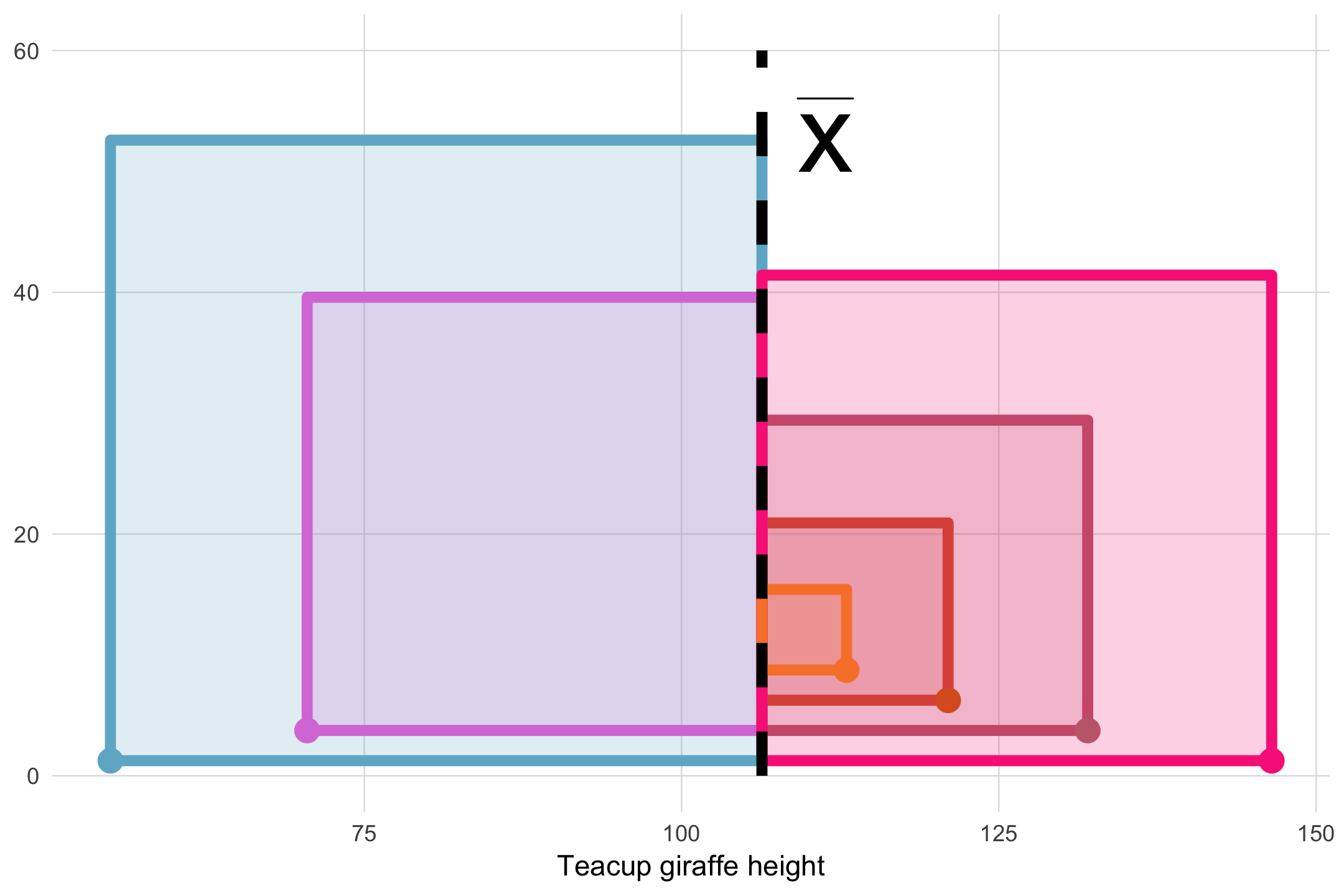
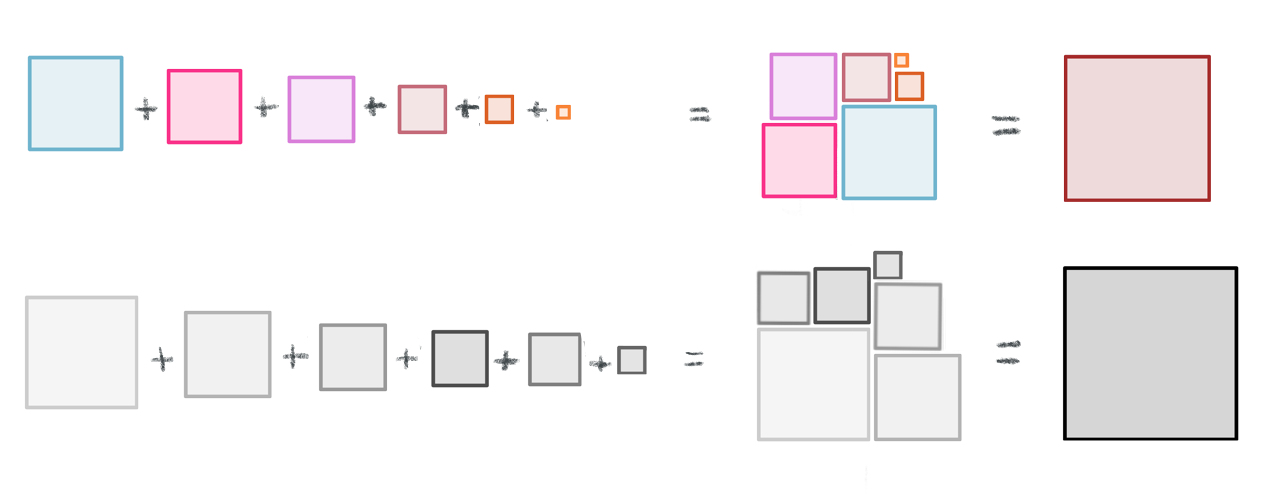
Therefore, when we calculate the sum of squares (and consequently, the variance and the standard deviation) using the sample mean \(\bar{x}\), we are most likely arriving at a value that is downwardly biased compared to what the true variance or standard deviation would be if we were able to know and use the population mean \(\mu\).
This is why we need to adjust our sample variance by diving by \(n-1\) instead of just \(N\). By diving by a smaller value (i.e. \(n-1\) instead of N), we ensure that the overall value of the variance and standard deviation will be a little larger, correcting for the downward bias we just described.
How badly might the sample variance be downwardly biased?: Well, it depends on how far away \(\bar{x}\) is from the true \(\mu\). The further away it is, the worse the downward bias will be!
Of course, we want to avoid having a very downwardly biased variance. What controls how far away \(\bar{x}\) is from \(\mu\)? The sample size! As pointed out previously, the larger the sample, the greater the likelihood that your sample mean will resemble the population mean.
Press Play on the animation below. The plot shows the relationship between bias in the variance, the sample size, and the distance between \(\bar{x}\) and \(\mu\). Each dot represents one out of a thousand random samples all from the same population. The vertical dotted line represents \(\mu\), and the horizontal dotted line represents the true population variance (animation inspired by Khan Academy video.)
When the samples whose means \(\bar{x}\) are far off from the true population mean, they tend to have downwardly biased variance.
Take a look at the points that are furthest away from the true population mean– the samples represented by these points primarily came from small sample sizes (dark blue dots).
The plot below shows the percentage of the true population variance that an uncorrected sample variance achieves on average. These data were generated by sampling from the same population as the animation above. This time the data have been grouped into bars by how many observations each random sample had. (Animation inspired by Khan Academy video)
Notice that the variances from smaller samples do the worst job of approaching 100% of the true variance. In fact, without correction the sample variance is downwardly biased by a factor of \(n/(n-1)\).
You can hover over the bars above to see what the average percentage of the true variance actually is for the different samples sizes. If we multiply this percentage by the correction, we fix the discrepancy between sample and population variance. We demonstrate this below for samples of size n = 3.
n = 3
correction = n/(n-1)
hover_value = 67.22902 # % value when hovering over bar for n = 3
# Apply correction
percent_of_true_variance <- hover_value * correction
percent_of_true_variance ## [1] 100.8435As we can see, the correction works by adjusting the downwardly biased sample variance to close to 100% of the true variance.
Try hovering over a few other bars and see yourself that correction works independent of the sample size. You can use the window below as a calculator to change the N and the hover values and then run the code.
This project was created entirely in RStudio using R Markdown and published on GitHub pages.