Covariance and Correlation
Module learning objectives
- Create a scatterplot using ggplot
- Identify the similarities and differences between calculating the variance and covariance
- Write a function for the covariance and Pearson’s correlation coefficient
- Interpret the meaning behind Pearson’s correlation correlation
- Describe the purpose of dividing by the product of the standard deviations when calculating the correlation.
Gathering data on another variable
Over the course of your time on the islands, you notice that the teacup giraffes seem to have an affinity for celery, which you have already used to entice so they come close enough for a height measurement. Suprisingly, one of the small ones had eaten so much of it! You decide to quantify how much celery each of the giraffes consumed to see if there is any relationship to height.
You systematically measure the amount of celery eaten and add it to your log of data, which is stored as a data frame called giraffe_data.
We can check out the first entries of the data frame by using the head( ) command:
head(giraffe_data)## Heights Celery_Eaten
## 1 7.038865 16.36129
## 2 13.154339 10.72354
## 3 8.086511 17.16798
## 4 8.159990 22.52115
## 5 6.004716 13.77993
## 6 9.455408 16.92304Make a scatter plot
It’s difficult to get an idea if there’s any relationship by just looking at the data frame. We learn so much more from creating a plot. Let’s revisit our newly acquired ggplot skills to make a scatter plot.
A lot of the code used previously can be re-used for the scatter plot. Two main differences are the following:
Because we now have an additional variable, we need to assign a
y =for theaes( )command withinggplot( ). Create the plot so thatCelery_Eatenwill be on the y-axis.Add (
+) ageom_point( )element instead ofgeom_hist( )
Also, we will add lines to our plot, representing the mean of each variable. Here’s how we’ll do that:
- Add a horizontal line by adding (
+) ageom_hline( )component. This takes the argumentyintercept =, which equals the value for where the horizontal line should cross the y-intercept.- Since we want to place this line at the mean of y variable (\({\bar{y}}\)), we can use the
mean( )function instead of specifying a numeric value directly.
- Since we want to place this line at the mean of y variable (\({\bar{y}}\)), we can use the
- Add a vertical line by following the same structure as above but using
geom_vline( )andxintercept =instead. This vertical line will represent the mean (\({\bar{x}}\)) of the heights.
Construct a scatter plot of the data using the window below:
Great, now you have a scatter plot! But recalling the email from your advisor the last time you plotted data, you decide you’d like to customize the look of the plot the same way you did when you created the ggplot histogram.
Play around with some aesthetics in the window below, and then run the solution to see what we chose.
Looking at the scatter plot, there seems to be a relationship between height and celery eaten, but you will need to quantify this more formally to be sure.
Relationship between two variables
How can the relationship between two variables (and its strength) be quantified? This can be done by assessing how the two variables change together – one such measure is the covariance.
The covariance elegantly combines the deviations of observations from two different variables into a single value. This is how it’s done:
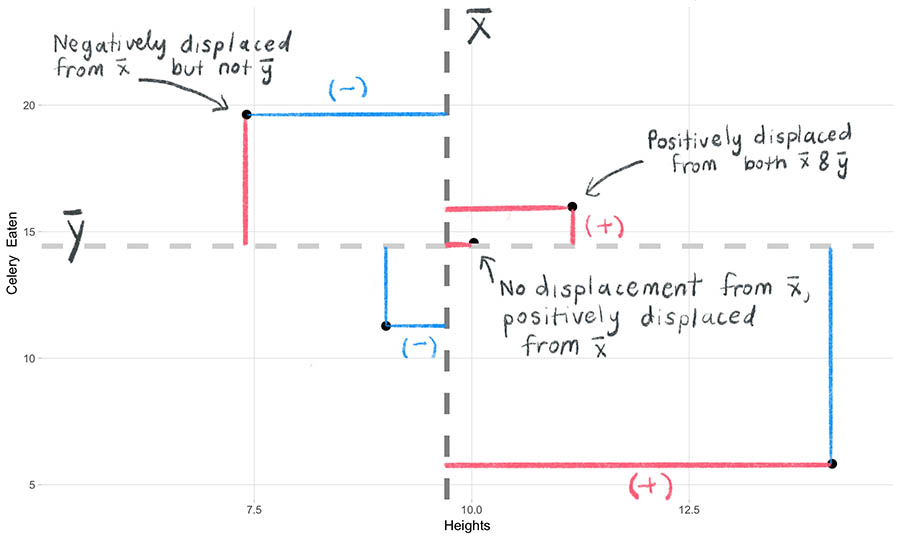
- As we did for the variance, we begin by measuring how far each observation lies from its mean. But unlike when we calculated the variance, each observation now includes two variables. We will need to calculate the observation’s distance from each variable’s mean. We call each distance the deviation scores on x and on y, respectively. Like the variance, the observation can fall above or below the mean, and as a result the corresponding deviation score will have either a positive or negative sign.
We observe this below with a subset of 5 points from our scatter plot. Positive deviations are shown in red, negative deviations in blue.
points
Why do we use the deviations? Because we want to know whether the x-values and y-values move together with respect to their means or not. For example, when an observation’s deviation on x is above \(\bar{x}\), will its deviation on y also be above \(\bar{y}\)? Using this line of thought, we can begin to systematically characterize how “together” the x and y values will change as we go through all observations.
Crossproduct
After obtaining the deviation scores, we need to combine them into a single measure. We do not simply combine the deviation scores themselves by adding (please see the page about the variance for a discussion of why this is). Instead, we take both deviation scores from the same observation and multiply them together to create a two-dimensional “shape” (analagous to when we multiplied a single deviation score by itself to create a square in the variance calculation).
NOTE: The resulting value is now on the order of a “squared” term. This will become important later.
- Multiply the two deviation scores. This is called the crossproduct. The shapes created by the crossproduct will serve as the “squared” terms that we can then use in the next step to sum and summarize the deviations into a single value.
The equation is shown below for the sample crossproduct of the deviation scores.
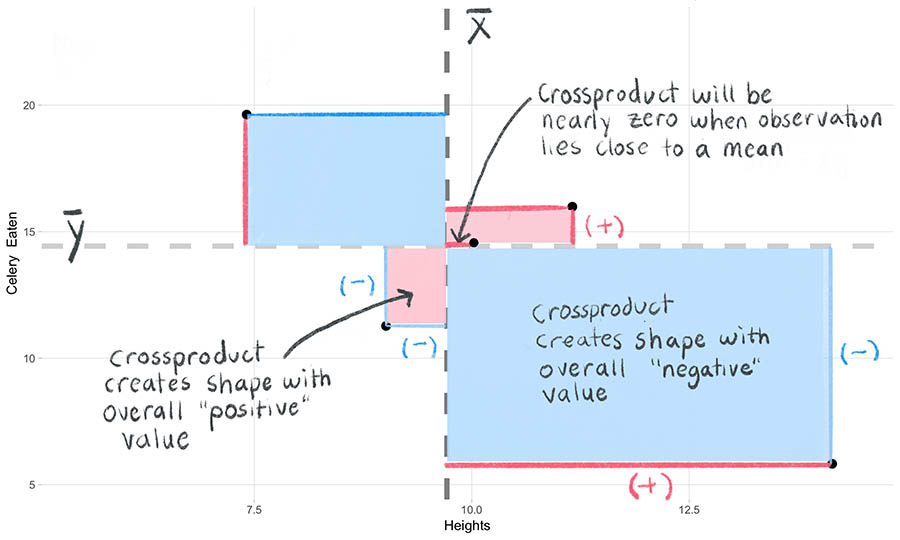
Let’s explore the attributes of the crossproduct:
First, we should note that the overall sign of the crossproduct will depend on whether or not the two x- and y- values from the same observation move in the same directions relative to their means. Look at the annotated plot below. The crossproducts will either create “negative” shapes (shown in blue) or “positive” shapes (in red). A third outcome is that the crossproduct could also be 0 – this will occur when an observation falls on the mean.
Second, the magnitude of the crossproduct will scale with the absolute value of the deviation scores. In other words, the further away both deviation scores are from their means, the larger the area of their shapes will be.
The animation below shows the “construction” of the crossproducts from the 5 observations we have been following:
- Sum the crossproducts. The sum of the crossproduct gives us a single number.
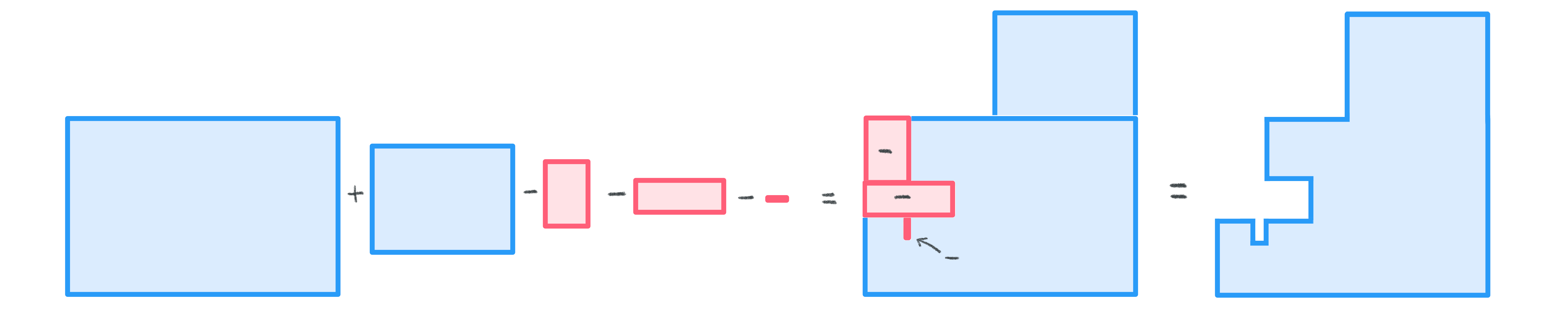
As we add the crossproducts, some of the “negative” and “positive” values of the shapes will cancel each other out. This is okay because this tells us important information about our two variables. If the negative and positive shapes cancel each other out completely, it would mean that there is no relationship. In most cases this will not happen, and the sum of the crossproducts will be positive or negative. In general, the larger the magnitude of the sum of the crossproducts, the more strongly the two variables move together. The equation is shown below.
Covariance
- We then divide the sum of the crossproduct by \(n-1\) (or \(N\) in the population equation) so that we have taken into account how many observations contributed to this quantity. (Why \(n-1\)? See here.) This final number is called the covariance, and its value tells us how much our two variables fluctuate together. The higher the absolute value, the stronger the relationship.
The equation for the covariance (abbreviated “cov”) of the variables x and y is shown below. As a preference of style, we multiply by \(\frac{1}{n-1}\) instead of dividing the entire term by \(n-1\).
Problem of interpretation
However, the covariance is not an intuitive value. Remember that we have been working with terms that are on the “squared” scale, which is not only difficult to interpret (just like the variance is) but it is also the product of two variables on possibly different scales. How could we interpret a covariance with units of millimeters*grams mean?
Another point to make is that value of the covariance will be vastly different if we had decided to change the units (millimeters vs centimeters, or grams vs kilograms).
As a result, the covariance is not an easy metric to work with or to compare with other covariances. So we need to standardize it!
Pearson correlation coefficient, \(r\)
How do we standardize the covariance?
The solution is to (1) take the standard deviations of each variable, (2) multiply them together, and (3) divide the covariance by this product – the resulting value is called the Pearson correlation coefficient. When referring to the population correlation coefficient, the symbol \(\rho\) (pronounced “rho”) is used. When referring to the sample correlation coefficient, a lowercase \(r\) is used (often called “Pearson’s r”).
Here is the equation for the population correlation:
What does the correlation mean?
We can interpret the correlation as a measure of the strength and direction of the relationship between two variables. It is a “standardized” version of the covariance.
- The correlation will always be between -1 and 1. At these extreme values, the two variables have the strongest relationship possible, in which each data point will fall exactly on a line. When the absolute value of the correlation coefficient approaches 0, the observations will be more “scattered”.
- The sign of the correlation coefficient indicates the direction of the linear relationship. When \(r\)= 0 there is no relationship between the variables. Look at the figure below to see what observations of different \(r\) values look like.

Your turn
Imagine you’re given a plot like the one below. What would you say it’s correlation value is? Try out your guess for a few plots, and if you need a hint to help you visualize, click Show trend line.
Code it up
- In the window below, write your own function to compute the sample covariance of two variables, and call it
my_covariance( ). - Then create a second function called
my_correlation( )in which you will compute the correlation of two variables. You may incorporate your functionmy_covariance( )in this step to save yourself some time. - Once you’ve created both functions, use them to compute the covariance and correlation between
HeightsandCelery_Eatenwithin the data framegiraffe_data. - Finally, compare your functions’ outputs with the base R functions for covariance,
cov( )andcor( ).
Remember, you will need to write both functions so that they will take two parameters, one for each variable. The parameters for my_covariance( ) have been setup for you.
Wow, you can see that there is a negative relationship between giraffe heights and how much celery teacup giraffes eat. Could this be due to celery being a negative calorie vegetable? Are these giraffes onto something?

The Standardizer
You can take a look at the animation below to see a conceptual summary of how correlation will standarize the covariance, translating it into an easily interpretable metric that will always be bound by -1 and 1.
Why divide by \(\sigma_x\sigma_y\)?
Well it’s complicated, (see here and here) but it builds on the mathematical principle that the covariance of x and y will never exceed the product of the standard deviations of x and y. This means that the maximum correlation value will occur when the absolute value of the covariance and the product of the standard deviations are equal.
If you don’t take our word for it, press play below to see what the relationship between \({s}_x{s}_y\) and \({cov(x,y)}\) looks like.
As you look at the plot above, you may have the following questions:
Why are there clearly defined boundaries?
Because at the edges is where the covariance is the greatest value that it can be– it is equal to the product of the standard deviations there.
The slope is 1 at this boundary.
Where in the plot do the strongest correlations end up?
- On the edges – when the absolute value of the numerator and denominator of the equation are equal– the quotient will = 1 (or negative 1, depending on the sign of the covariance in the numerator).
Things to think about
Correlation does not capture relationships that are not linear: If the relationship is not linear, then correlation will not be meaningful. Check out the plot below. There is a clear U-shaped relationship between the two variables, but the correlation coefficient for these data is very close to 0. To measure non-linear relationships a different metric must be used.
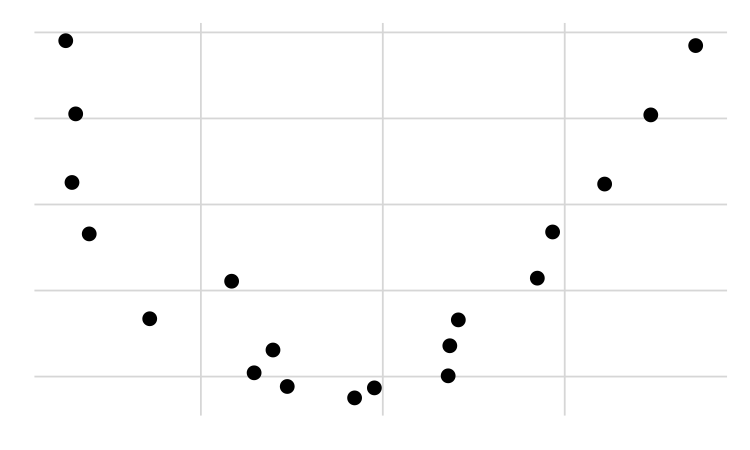
Correlation is not causation: Just because there is a linear relationship between two variables does not mean we have evidence that one variable causes the other. Even if there really was a cause-and-effect relationship, with correlation we cannot say which variable is the cause and which is the effect. It’s also possible that there exists some other unmeasured variable affecting the linear relationship we observe. And of course, any apparent relationship may be due to nothing more than random chance.
This project was created entirely in RStudio using R Markdown and published on GitHub pages.